mirror of
https://github.com/AAndyProgram/SCrawler.git
synced 2026-06-08 01:35:24 +00:00
2023.6.9.0
@@ -206,6 +206,11 @@ The Reddit parser can parse data without cookies, but you can add it if you like
|
||||
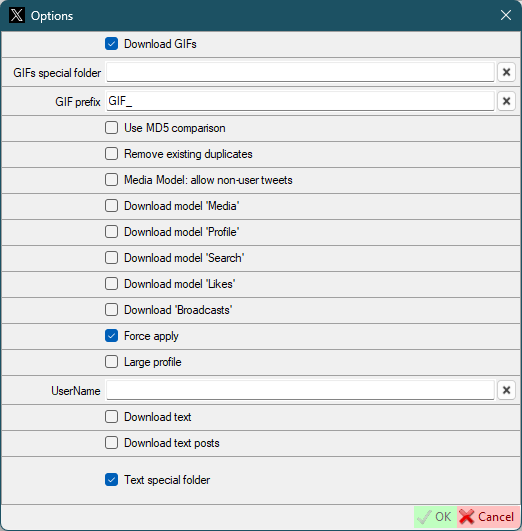
- `GIF prefix` - *same as default twitter settings, but for this user*
|
||||
- `Use MD5 comparison` - *same as default twitter settings, but for this user*
|
||||
- `Remove existing duplicates` - Existing files will be checked for duplicates and duplicates removed. **Works only on the first activation 'Use MD5 comparison'.**
|
||||
- `Download model 'Media'` - Download the data using the `https://twitter.com/UserName/media` command.
|
||||
- `Download model 'Profile'` - Download the data using the `https://twitter.com/UserName` command.
|
||||
- `Download model 'Search'` - Download the data using the `https://twitter.com/search?q=from:UserName+include:nativeretweets` command.
|
||||
|
||||
**You don't need to change the `Download model` parameters. During the first download SCrawler will determine the optimal parameters. These are the command parameters for gallery-dl. Change them only if you know what you are doing.**
|
||||
|
||||
|
||||
|
||||
|
||||
Reference in New Issue
Block a user