mirror of
https://github.com/AAndyProgram/SCrawler.git
synced 2026-06-08 01:35:24 +00:00
2024.5.18.0
@@ -156,6 +156,7 @@ interface ISiteSettings: IDisposable
|
|||||||
string Site {get;};
|
string Site {get;};
|
||||||
string CMDEncoding {get; set;};
|
string CMDEncoding {get; set;};
|
||||||
IEnumerable<String> EnvironmentPrograms {get; set;};
|
IEnumerable<String> EnvironmentPrograms {get; set;};
|
||||||
|
string UserAgentDefault {get; set;};
|
||||||
void EnvironmentProgramsUpdated()
|
void EnvironmentProgramsUpdated()
|
||||||
string AccountName {get; set;};
|
string AccountName {get; set;};
|
||||||
bool Temporary {get; set;};
|
bool Temporary {get; set;};
|
||||||
@@ -196,6 +197,8 @@ interface ISiteSettings: IDisposable
|
|||||||
|
|
||||||
`EnvironmentPrograms` - user-selected paths to programs such as yt-dlp, gallery-dl, ffmpeg, curl, etc.
|
`EnvironmentPrograms` - user-selected paths to programs such as yt-dlp, gallery-dl, ffmpeg, curl, etc.
|
||||||
|
|
||||||
|
`UserAgentDefault` - UserAgent that the user has configured in the global settings form
|
||||||
|
|
||||||
`EnvironmentProgramsUpdated` - this function will be called when `EnvironmentPrograms` or `CMDEncoding` changes
|
`EnvironmentProgramsUpdated` - this function will be called when `EnvironmentPrograms` or `CMDEncoding` changes
|
||||||
|
|
||||||
`AccountName` property set before calling the `BeginInit` function.
|
`AccountName` property set before calling the `BeginInit` function.
|
||||||
|
|||||||
47
Settings.md
47
Settings.md
@@ -290,16 +290,18 @@ The Reddit parser can parse data without cookies, but you can add it if you like
|
|||||||
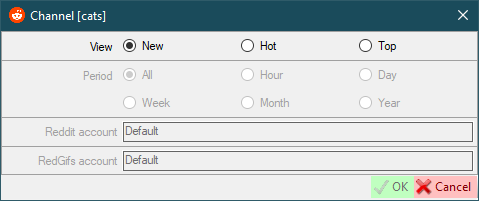
|

|
||||||
|
|
||||||
## Twitter
|
## Twitter
|
||||||
|
- New user defaults
|
||||||
- `Use the appropriate model` - Use the appropriate model for new users. If disabled, all download models will be used for the first download. Next, the appropriate download model will be automatically selected. Otherwise the appropriate download model will be selected right from the start.
|
- `Use the appropriate model` - Use the appropriate model for new users. If disabled, all download models will be used for the first download. Next, the appropriate download model will be automatically selected. Otherwise the appropriate download model will be selected right from the start.
|
||||||
- `New endpoint: search` - use new endpoint argument (`-o search-endpoint=graphql`) for the search model.
|
|
||||||
- `New endpoint: profiles` - use new endpoint argument (`-o search-endpoint=graphql`) for the profile models.
|
|
||||||
- `Abort on limit` - abort twitter downloading when limit is reached.
|
|
||||||
- `Download already parsed` - download already parsed content on abort.
|
|
||||||
- `Media Model: allow non-user tweets` - allow downloading non-user tweets in the media-model.
|
- `Media Model: allow non-user tweets` - allow downloading non-user tweets in the media-model.
|
||||||
- `Download GIFs` - *(default for new users) this can also be configured for a specific user.*
|
- `Download GIFs` - *(default for new users) this can also be configured for a specific user.*
|
||||||
- `GIFs special folder` - *(default for new users)* Put the GIFs in a special folder. **This is a folder name, not an absolute path** (examples: `SomeFolderName`, `SomeFolderName\SomeFolderName2`). This folder(s) will be created relative to the user's root folder. *This can also be configured for a specific user.*
|
- `GIFs special folder` - *(default for new users)* Put the GIFs in a special folder. **This is a folder name, not an absolute path** (examples: `SomeFolderName`, `SomeFolderName\SomeFolderName2`). This folder(s) will be created relative to the user's root folder. *This can also be configured for a specific user.*
|
||||||
- `GIF prefix` - *(default for new users)* This prefix will be added to the beginning of the filename. *This can also be configured for a specific user.*
|
- `GIF prefix` - *(default for new users)* This prefix will be added to the beginning of the filename. *This can also be configured for a specific user.*
|
||||||
- `Use MD5 comparison` - *(default for new users)* each image will be checked for existence using MD5 (this may be suitable for the users who post the same image many times). *This can also be configured for a specific user.*
|
- `Use MD5 comparison` - *(default for new users)* each image will be checked for existence using MD5 (this may be suitable for the users who post the same image many times). *This can also be configured for a specific user.*
|
||||||
|
- Downloading
|
||||||
|
- `New endpoint: search` - use new endpoint argument (`-o search-endpoint=graphql`) for the search model.
|
||||||
|
- `New endpoint: profiles` - use new endpoint argument (`-o search-endpoint=graphql`) for the profile models.
|
||||||
|
- `Abort on limit` - abort twitter downloading when limit is reached.
|
||||||
|
- `Download already parsed` - download already parsed content on abort.
|
||||||
- `Concurrent downloads` - the number of concurrent downloads.
|
- `Concurrent downloads` - the number of concurrent downloads.
|
||||||
|
|
||||||
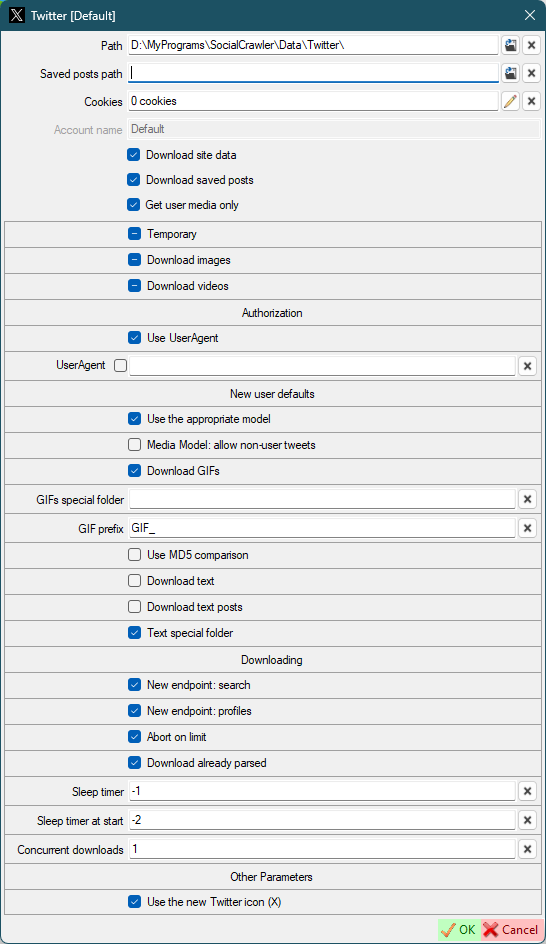
|

|
||||||
@@ -319,6 +321,7 @@ The Reddit parser can parse data without cookies, but you can add it if you like
|
|||||||
- `Download model 'Media'` - Download the data using the `https://twitter.com/UserName/media` command.
|
- `Download model 'Media'` - Download the data using the `https://twitter.com/UserName/media` command.
|
||||||
- `Download model 'Profile'` - Download the data using the `https://twitter.com/UserName` command.
|
- `Download model 'Profile'` - Download the data using the `https://twitter.com/UserName` command.
|
||||||
- `Download model 'Search'` - Download the data using the `https://twitter.com/search?q=from:UserName+include:nativeretweets` command.
|
- `Download model 'Search'` - Download the data using the `https://twitter.com/search?q=from:UserName+include:nativeretweets` command.
|
||||||
|
- `Download model 'Likes'` - Download the data using the `https://twitter.com/UserName/likes` command.
|
||||||
- `Force apply` - force overrides the default parameters (download model) for the first download (applies to first download only).
|
- `Force apply` - force overrides the default parameters (download model) for the first download (applies to first download only).
|
||||||
|
|
||||||
**You don't need to change the `Download model` parameters. During the first download SCrawler will determine the optimal parameters. These are the command parameters for gallery-dl. Change them only if you know what you are doing.**
|
**You don't need to change the `Download model` parameters. During the first download SCrawler will determine the optimal parameters. These are the command parameters for gallery-dl. Change them only if you know what you are doing.**
|
||||||
@@ -328,15 +331,17 @@ The Reddit parser can parse data without cookies, but you can add it if you like
|
|||||||
## OnlyFans
|
## OnlyFans
|
||||||
|
|
||||||
**[Partial support](#paid-sites-partial-support)**
|
**[Partial support](#paid-sites-partial-support)**
|
||||||
|
- Authorization
|
||||||
- `Download timeline` - download user timeline
|
|
||||||
- `Download stories` - download profile stories if they exists
|
|
||||||
- `Download highlights` - download profile highlights if they exists
|
|
||||||
- `Download chat` - download unlocked chat media
|
|
||||||
- `user-id`, `x-bc`, `app-token`, `sec-sc-ua`, `UserAgent` - required headers ([how to find](#how-to-find-headers) (the request you need must start with `posts?limit=.....`))
|
- `user-id`, `x-bc`, `app-token`, `sec-sc-ua`, `UserAgent` - required headers ([how to find](#how-to-find-headers) (the request you need must start with `posts?limit=.....`))
|
||||||
- `Use old authorization rules` - use old dynamic rules (from 'DATAHOARDERS') or new ones (from 'DIGITALCRIMINALS'). **Change this value only if you know what you are doing.**
|
- `Use old authorization rules` - use old dynamic rules (from 'DATAHOARDERS') or new ones (from 'DIGITALCRIMINALS'). **Change this value only if you know what you are doing.**
|
||||||
- `Dynamic rules update` - 'Dynamic rules' update interval (minutes). Default: `1440`.
|
- `Dynamic rules update` - 'Dynamic rules' update interval (minutes). Default: `1440`.
|
||||||
- `Dynamic rules` - overwrite 'Dynamic rules' with this URL. **Change this value only if you know what you are doing.**
|
- `Dynamic rules` - overwrite 'Dynamic rules' with this URL. **Change this value only if you know what you are doing.**
|
||||||
|
- New user defaults
|
||||||
|
- `Download timeline` - download user timeline
|
||||||
|
- `Download stories` - download profile stories if they exists
|
||||||
|
- `Download highlights` - download profile highlights if they exists
|
||||||
|
- `Download chat` - download unlocked chat media
|
||||||
|
- OF-Scraper support
|
||||||
- `OF-Scraper path` - the path to the `ofscraper.exe`
|
- `OF-Scraper path` - the path to the `ofscraper.exe`
|
||||||
- `mp4decrypt path` - the path to the `mp4decrypt.exe`
|
- `mp4decrypt path` - the path to the `mp4decrypt.exe`
|
||||||
- `key-mode-default` - change the key-mode. Default: `cdrm`. **Change this value only if you know what you are doing.**
|
- `key-mode-default` - change the key-mode. Default: `cdrm`. **Change this value only if you know what you are doing.**
|
||||||
@@ -377,13 +382,16 @@ The Reddit parser can parse data without cookies, but you can add it if you like
|
|||||||
**No! SCrawler is not a hacking program. Just a downloader.**
|
**No! SCrawler is not a hacking program. Just a downloader.**
|
||||||
|
|
||||||
## Mastodon
|
## Mastodon
|
||||||
|
- Authorization
|
||||||
- `My Domain` - your account domain without `https://` (for example, `mastodon.social`)
|
- `My Domain` - your account domain without `https://` (for example, `mastodon.social`)
|
||||||
- `Authorization` - `Authorization` request header. Must start with `Bearer ` word. [How to find](#how-to-find-headers).
|
- `Authorization` - `Authorization` request header. Must start with `Bearer ` word. [How to find](#how-to-find-headers).
|
||||||
- `Token` - `x-csrf-token` request header. [How to find](#how-to-find-headers).
|
- `Token` - `x-csrf-token` request header. [How to find](#how-to-find-headers).
|
||||||
|
- New user defaults
|
||||||
- `Download GIFs` - *(default for new users) this can also be configured for a specific user.*
|
- `Download GIFs` - *(default for new users) this can also be configured for a specific user.*
|
||||||
- `GIFs special folder` - *(default for new users)* Put the GIFs in a special folder. **This is a folder name, not an absolute path** (examples: `SomeFolderName`, `SomeFolderName\SomeFolderName2`). This folder(s) will be created relative to the user's root folder. *This can also be configured for a specific user.*
|
- `GIFs special folder` - *(default for new users)* Put the GIFs in a special folder. **This is a folder name, not an absolute path** (examples: `SomeFolderName`, `SomeFolderName\SomeFolderName2`). This folder(s) will be created relative to the user's root folder. *This can also be configured for a specific user.*
|
||||||
- `GIF prefix` - *(default for new users)* This prefix will be added to the beginning of the filename. *This can also be configured for a specific user.*
|
- `GIF prefix` - *(default for new users)* This prefix will be added to the beginning of the filename. *This can also be configured for a specific user.*
|
||||||
- `Use MD5 comparison` - *(default for new users)* each image will be checked for existence using MD5 (this may be suitable for the users who post the same image many times). *This can also be configured for a specific user.*
|
- `Use MD5 comparison` - *(default for new users)* each image will be checked for existence using MD5 (this may be suitable for the users who post the same image many times). *This can also be configured for a specific user.*
|
||||||
|
- Other parameters
|
||||||
- `User related to my domain` - open user profiles and user posts through my domain.
|
- `User related to my domain` - open user profiles and user posts through my domain.
|
||||||
|
|
||||||
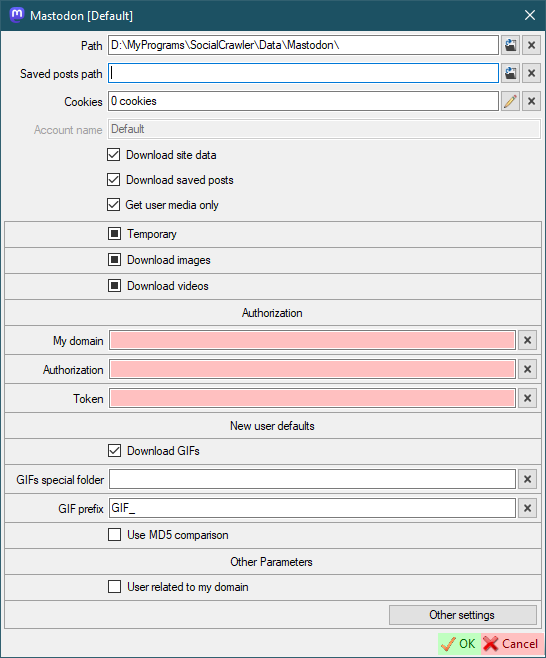
|

|
||||||
@@ -403,22 +411,27 @@ To support the downloading of this site you should add the Mastodon domain to th
|
|||||||
## Instagram
|
## Instagram
|
||||||
- Authorization
|
- Authorization
|
||||||
- `x-csrftoken` - [how to find](#how-to-find-headers) *(can be automatically extracted from cookies)*
|
- `x-csrftoken` - [how to find](#how-to-find-headers) *(can be automatically extracted from cookies)*
|
||||||
- `x-ig-app-id`, `ix-ig-www-claim`, `sec-ch-ua`, `sec-ch-ua-full-version-list`, `sec-ch-ua-platform-version`, `UserAgent` - [how to find](#how-to-find-headers)
|
- `x-ig-app-id`, `x-absd-id`, `ix-ig-www-claim`, `sec-ch-ua`, `sec-ch-ua-full-version-list`, `sec-ch-ua-platform-version`, `UserAgent` - [how to find](#how-to-find-headers)
|
||||||
- `Use GraphQL to download` - Use GraphQL to download data instead of the current query algorithm.
|
- `Use GraphQL to download` - Use GraphQL to download data instead of the current query algorithm.
|
||||||
|
- Download data
|
||||||
- `Download timeline` - Download timeline *(with this setting, you can simply enable/disable the downloading of some Instagram blocks)*
|
- `Download timeline` - Download timeline *(with this setting, you can simply enable/disable the downloading of some Instagram blocks)*
|
||||||
- `Download reels` - Download reels *(with this setting, you can simply enable/disable the downloading of some Instagram blocks)*
|
- `Download reels` - Download reels *(with this setting, you can simply enable/disable the downloading of some Instagram blocks)*
|
||||||
- `Download stories` - Download stories *(with this setting, you can simply enable/disable the downloading of some Instagram blocks)*
|
- `Download stories` - Download stories *(with this setting, you can simply enable/disable the downloading of some Instagram blocks)*
|
||||||
- `Download stories: user` - Download active (non-pinned) user stories *(with this setting, you can simply enable/disable the downloading of some Instagram blocks)*
|
- `Download stories: user` - Download active (non-pinned) user stories *(with this setting, you can simply enable/disable the downloading of some Instagram blocks)*
|
||||||
- `Download tagged` - Download tagged posts *(with this setting, you can simply enable/disable the downloading of some Instagram blocks)*
|
- `Download tagged` - Download tagged posts *(with this setting, you can simply enable/disable the downloading of some Instagram blocks)*
|
||||||
|
- Timers
|
||||||
- `Request timer (any)` - the timer (in milliseconds) that SCrawler should wait before executing the next request. The default value is 1'000. **It is highly recommended not to change the default value.**
|
- `Request timer (any)` - the timer (in milliseconds) that SCrawler should wait before executing the next request. The default value is 1'000. **It is highly recommended not to change the default value.**
|
||||||
- `Request timer` - this is the time value (in milliseconds) the program will wait before processing the next `Request time counter` request (**it is highly recommended not to change this default value**)
|
- `Request timer` - this is the time value (in milliseconds) the program will wait before processing the next `Request time counter` request (**it is highly recommended not to change this default value**)
|
||||||
- `Request time counter` - how many requests will be sent to Instagram before the program waits `Request timer` milliseconds (**it is highly recommended not to change this default value**)
|
- `Request time counter` - how many requests will be sent to Instagram before the program waits `Request timer` milliseconds (**it is highly recommended not to change this default value**)
|
||||||
- `Post limit timer` - this is the time value (in milliseconds) the program will wait before processing the next request after 195 requests (**it is highly recommended not to change this default value**)
|
- `Post limit timer` - this is the time value (in milliseconds) the program will wait before processing the next request after 195 requests (**it is highly recommended not to change this default value**)
|
||||||
|
- New user defaults
|
||||||
- `Get timeline` - default value for new users
|
- `Get timeline` - default value for new users
|
||||||
- `Get reels` - default value for new users
|
- `Get reels` - default value for new users
|
||||||
- `Get stories` - default value for new users
|
- `Get stories` - default value for new users
|
||||||
- `Get stories: user` - default value for new users
|
- `Get stories: user` - default value for new users
|
||||||
- `Get tagged photos` - default value for new users
|
- `Get tagged photos` - default value for new users
|
||||||
|
- Other parameters
|
||||||
|
- `DownDetector` - Use 'DownDetector' to determine if the site is accessible. `-1` to disable. The value represents the average number of error reports over the last 4 hours.
|
||||||
- `Tagged notify limit` - Limit of new tagged posts when you receive a notification (read more [here](#instagram-tagged-posts-limit))
|
- `Tagged notify limit` - Limit of new tagged posts when you receive a notification (read more [here](#instagram-tagged-posts-limit))
|
||||||
|
|
||||||
**If an error occurred and the log told you that you need to update your credentials, you also need to enable the disabled functions (`Download timeline`, `Download stories`) back.**
|
**If an error occurred and the log told you that you need to update your credentials, you also need to enable the disabled functions (`Download timeline`, `Download stories`) back.**
|
||||||
@@ -519,9 +532,12 @@ result_cancel-->[*]
|
|||||||
```
|
```
|
||||||
|
|
||||||
## Threads
|
## Threads
|
||||||
|
- Authorization
|
||||||
- `x-csrftoken` - [how to find](#how-to-find-headers)
|
- `x-csrftoken` - [how to find](#how-to-find-headers)
|
||||||
- `x-ig-app-id`, `x-asbd-id`, `sec-ch-ua`, `sec-ch-ua-full-version-list`, `sec-ch-ua-platform-version`, `UserAgent` - [how to find](#how-to-find-headers)
|
- `x-ig-app-id`, `x-asbd-id`, `sec-ch-ua`, `sec-ch-ua-full-version-list`, `sec-ch-ua-platform-version`, `UserAgent` - [how to find](#how-to-find-headers)
|
||||||
|
- Timers
|
||||||
- `Request timer (any)` - the timer (in milliseconds) that SCrawler should wait before executing the next request. The default value is 1'000. **It is highly recommended not to change the default value.**
|
- `Request timer (any)` - the timer (in milliseconds) that SCrawler should wait before executing the next request. The default value is 1'000. **It is highly recommended not to change the default value.**
|
||||||
|
- Download
|
||||||
- `Download data` - The internal value indicates that site data should be downloaded. It becomes unchecked when the site returns an error. When you update your credentials, you need to checked this check box.
|
- `Download data` - The internal value indicates that site data should be downloaded. It becomes unchecked when the site returns an error. When you update your credentials, you need to checked this check box.
|
||||||
|
|
||||||
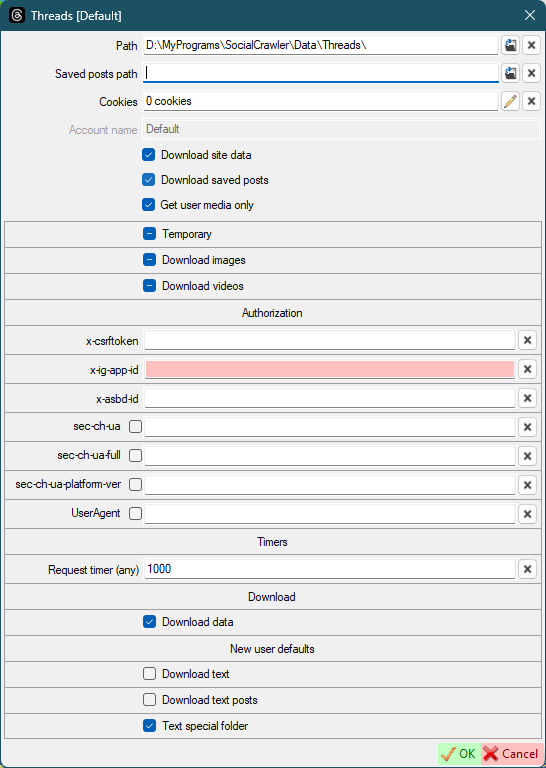
|

|
||||||
@@ -531,8 +547,15 @@ result_cancel-->[*]
|
|||||||
- [`headers`](#how-to-find-headers)
|
- [`headers`](#how-to-find-headers)
|
||||||
|
|
||||||
## Facebook
|
## Facebook
|
||||||
|
- Authorization
|
||||||
- `x-ig-app-id`, `x-asbd-id`, `Accept`, `sec-ch-ua`, `sec-ch-ua-full-version-list`, `sec-ch-ua-platform`, `sec-ch-ua-platform-version`, `UserAgent` - [how to find](#how-to-find-headers)
|
- `x-ig-app-id`, `x-asbd-id`, `Accept`, `sec-ch-ua`, `sec-ch-ua-full-version-list`, `sec-ch-ua-platform`, `sec-ch-ua-platform-version`, `UserAgent` - [how to find](#how-to-find-headers)
|
||||||
|
- New user defaults
|
||||||
|
- `Download photos`
|
||||||
|
- `Download videos`
|
||||||
|
- `Download stories`
|
||||||
|
- Timers
|
||||||
- `Request timer (any)` - the timer (in milliseconds) that SCrawler should wait before executing the next request. The default value is 1'000. **It is highly recommended not to change the default value.**
|
- `Request timer (any)` - the timer (in milliseconds) that SCrawler should wait before executing the next request. The default value is 1'000. **It is highly recommended not to change the default value.**
|
||||||
|
- Download
|
||||||
- `Download data` - The internal value indicates that site data should be downloaded. It becomes unchecked when the site returns an error. When you update your credentials, you need to checked this check box.
|
- `Download data` - The internal value indicates that site data should be downloaded. It becomes unchecked when the site returns an error. When you update your credentials, you need to checked this check box.
|
||||||
|
|
||||||
The `Accept` and `UserAgent` headers must be obtained from the page `https://facebook.com/<USERNAME>`.
|
The `Accept` and `UserAgent` headers must be obtained from the page `https://facebook.com/<USERNAME>`.
|
||||||
@@ -577,8 +600,10 @@ The `User ID` and `UserAgent` values must be obtained from the page `https://jus
|
|||||||
|
|
||||||
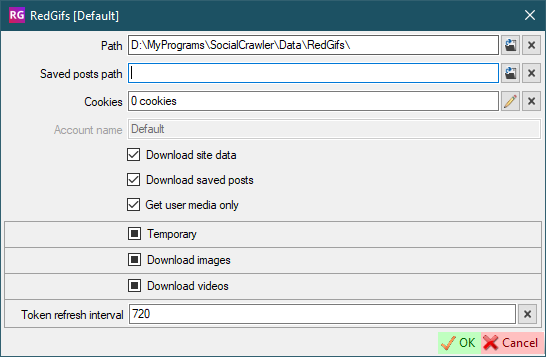
## RedGifs
|
## RedGifs
|
||||||
- `Token refresh interval` - Interval (in minutes) to refresh the token
|
- `Token refresh interval` - Interval (in minutes) to refresh the token
|
||||||
- `Token` - "Bearer" token ([how to find](#how-to-find-redgifs-token))
|
<!--
|
||||||
|
- `Token` - "Bearer" token
|
||||||
- `UserAgent` - UserAgent to use in requests ([how to find](#how-to-find-useragent))
|
- `UserAgent` - UserAgent to use in requests ([how to find](#how-to-find-useragent))
|
||||||
|
-->
|
||||||
|
|
||||||
|

|
||||||
|
|
||||||
|
|||||||
Reference in New Issue
Block a user