mirror of
https://github.com/AAndyProgram/SCrawler.git
synced 2026-06-08 01:35:24 +00:00
2025.2.25.0
1
Home.md
1
Home.md
@@ -148,6 +148,7 @@ Load sessions:
|
||||
- `Reset current session` - a new file will be created for the current session
|
||||
- `Merge special feeds` - merge multiple special feeds into one
|
||||
- `Select all/none`
|
||||
- `Invert selection`
|
||||
- `Save current view`
|
||||
- `Load view (from saved)` - load one of your previously saved views
|
||||
|
||||
|
||||
@@ -310,6 +310,7 @@ interface IPluginContentProvider : IDisposable
|
||||
ISiteSettings Settings {get; set;};
|
||||
string AccountName {get; set;};
|
||||
string Name {get; set;};
|
||||
string NameTrue {get; set;};
|
||||
string ID {get; set;};
|
||||
string Options {get; set;};
|
||||
bool ParseUserMediaOnly {get; set;};
|
||||
@@ -344,7 +345,8 @@ Raise the `ProgressPreMaximumChanged` event when the amount of parse content has
|
||||
|
||||
See the [Thrower](#IThrower) , [LogProvider](#ILogProvider) and [Settings](#ISiteSettings) property environments in their respective chapters. **Don't set these properties manually.** They will be set by SCrawler.
|
||||
|
||||
`Name` is the username returned from the settings class when a new user is created.
|
||||
`Name` is the username returned from the settings class when a new user is created. **This property cannot be changed. To change the user name, use the `NameTrue` property.**
|
||||
`NameTrue` is a compatible property. It's used when a user changes their name.
|
||||
`ID` is the user ID on the site.
|
||||
`UserDescription` is the user description.
|
||||
`UserExists` and `UserSuspended` are properties indicating that the user is exists/suspended on the site.
|
||||
|
||||
58
Settings.md
58
Settings.md
@@ -7,7 +7,6 @@
|
||||
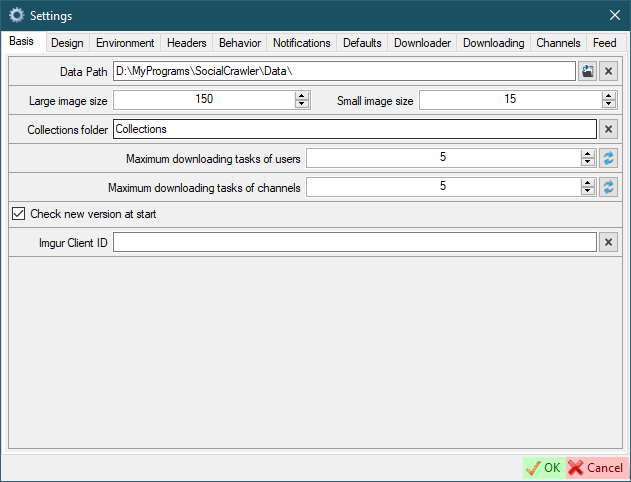
- `Maximum download tasks of users` - the number of simultaneously downloading profiles.
|
||||
- `Maximum download tasks of channels` - the number of simultaneously downloading channels.
|
||||
- `Check new version at start`
|
||||
- `UserAgent` - default UserAgent to use in requests ([how to find](#how-to-find-useragent)). This is not a required field. Use it if you need to replace the UserAgent for all sites. A restart of SCrawler is required to take effect.
|
||||
- `Imgur Client ID` - Imgur client ID to Bypass NSFW protection and download galleries
|
||||
|
||||
|
||||
@@ -166,6 +165,7 @@ Red highlight means that the field is required or you have entered an incorrect
|
||||
|
||||
- [Reddit](#reddit-requirements)
|
||||
- [Twitter](#twitter-requirements)
|
||||
- [Bluesky](#bluesky-requirements)
|
||||
- [OnlyFans](#onlyfans-requirements)
|
||||
- [Mastodon](#mastodon-requirements)
|
||||
- [Instagram](#instagram-requirements)
|
||||
@@ -217,7 +217,7 @@ ffmpeg is required for several sites like Reddit, PornHub, XHamster, XVIDEOS, et
|
||||
|
||||
### Gallery-dl
|
||||
|
||||
Version **1.28.3** ([release](https://github.com/mikf/gallery-dl/releases/tag/v1.28.3); [exe](https://github.com/mikf/gallery-dl/releases/download/v1.28.3/gallery-dl.exe))
|
||||
Version **1.28.5** ([release](https://github.com/mikf/gallery-dl/releases/tag/v1.28.5); [exe](https://github.com/mikf/gallery-dl/releases/download/v1.28.5/gallery-dl.exe))
|
||||
|
||||
**The following sites use gallery-dl:**
|
||||
- [Pinterest](#pinterest)
|
||||
@@ -225,10 +225,10 @@ Version **1.28.3** ([release](https://github.com/mikf/gallery-dl/releases/tag/v1
|
||||
|
||||
### YT-DLP
|
||||
|
||||
Version **2024.12.23** ([release](https://github.com/yt-dlp/yt-dlp/releases/tag/2024.12.23))
|
||||
Version **2025.02.19** ([release](https://github.com/yt-dlp/yt-dlp/releases/tag/2025.02.19))
|
||||
|
||||
- x64 version - [exe](https://github.com/yt-dlp/yt-dlp/releases/download/2024.12.23/yt-dlp.exe)
|
||||
- x86 version - [exe](https://github.com/yt-dlp/yt-dlp/releases/download/2024.12.23/yt-dlp_x86.exe)
|
||||
- x64 version - [exe](https://github.com/yt-dlp/yt-dlp/releases/download/2025.02.19/yt-dlp.exe)
|
||||
- x86 version - [exe](https://github.com/yt-dlp/yt-dlp/releases/download/2025.02.19/yt-dlp_x86.exe)
|
||||
|
||||
**The following sites use yt-dlp:**
|
||||
- [YouTube](#youtube)
|
||||
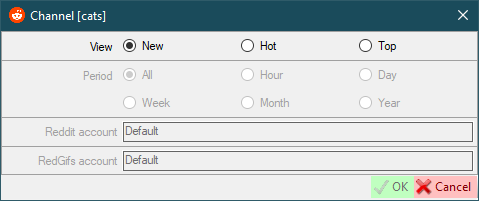
@@ -307,19 +307,25 @@ The Reddit parser can parse data without cookies, but you can add it if you like
|
||||
|
||||
|
||||
## Twitter
|
||||
- Authorization
|
||||
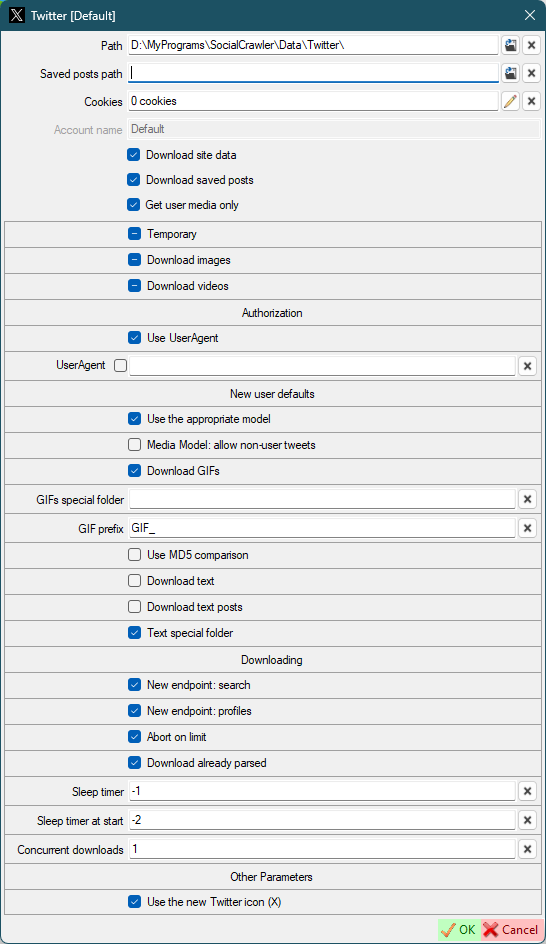
- `Use UserAgent` - use UserAgent in requests
|
||||
- `UserAgent`
|
||||
- New user defaults
|
||||
- `Use the appropriate model` - Use the appropriate model for new users. If disabled, all download models will be used for the first download. Next, the appropriate download model will be automatically selected. Otherwise the appropriate download model will be selected right from the start.
|
||||
- `Use the appropriate model` - use the appropriate model for new users. If disabled, all download models will be used for the first download. Next, the appropriate download model will be automatically selected. Otherwise the appropriate download model will be selected right from the start.
|
||||
- `Media Model: allow non-user tweets` - allow downloading non-user tweets in the media-model.
|
||||
- `Download GIFs` - *(default for new users) this can also be configured for a specific user.*
|
||||
- `GIFs special folder` - *(default for new users)* Put the GIFs in a special folder. **This is a folder name, not an absolute path** (examples: `SomeFolderName`, `SomeFolderName\SomeFolderName2`). This folder(s) will be created relative to the user's root folder. *This can also be configured for a specific user.*
|
||||
- `GIF prefix` - *(default for new users)* This prefix will be added to the beginning of the filename. *This can also be configured for a specific user.*
|
||||
- `GIF prefix` - *(default for new users)* this prefix will be added to the beginning of the filename. *This can also be configured for a specific user.*
|
||||
- `Use MD5 comparison` - *(default for new users)* each image will be checked for existence using MD5 (this may be suitable for the users who post the same image many times). *This can also be configured for a specific user.*
|
||||
- Downloading
|
||||
- `New endpoint: search` - use new endpoint argument (`-o search-endpoint=graphql`) for the search model.
|
||||
- `New endpoint: profiles` - use new endpoint argument (`-o search-endpoint=graphql`) for the profile models.
|
||||
- `Abort on limit` - abort twitter downloading when limit is reached.
|
||||
- `Download already parsed` - download already parsed content on abort.
|
||||
- `Sleep timer` - use sleep timer in requests. You can set a timer value (in seconds) to wait before each subsequent request. `-1` to disable and use the default algorithm. Default: `20`. Read more [here](#twitter-sleep-timers).
|
||||
- `Sleep timer at start` - set a sleep timer (in seconds) before the first request. `-1` to disable. `-2` to use the `Sleep timer` value. Default: `-2`
|
||||
- `Concurrent downloads` - the number of concurrent downloads.
|
||||
- `Use the new Twitter icon (X)` - *restart SCrawler to take effect*
|
||||
|
||||
|
||||
|
||||
@@ -329,6 +335,10 @@ The Reddit parser can parse data without cookies, but you can add it if you like
|
||||
|
||||
**Attention! If you are trying to download a community, uncheck the `Get user media only` flag!**
|
||||
|
||||
### Twitter sleep timers
|
||||
|
||||
To completely download a large profile, you can use sleep timers. The sleep timer value is the time in seconds that the SCrawler waits before executing the next request. The optimal and safe value is 20 seconds. Sleep timers are disabled by default because they are slow down download. But if you have too many Twitter profiles in SC, I recommend enabling them. If you enable them, I also recommend enabling `UserAgent`.
|
||||
|
||||
### Twitter user settings
|
||||
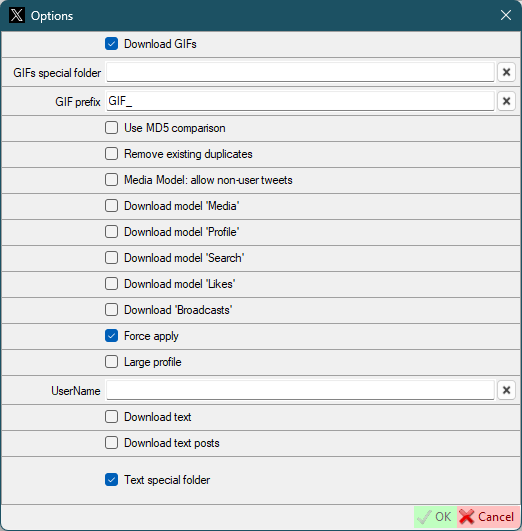
- `Download GIFs` - *same as default twitter settings, but for this user*
|
||||
- `GIFs special folder` - *same as default twitter settings, but for this user*
|
||||
@@ -347,6 +357,16 @@ The Reddit parser can parse data without cookies, but you can add it if you like
|
||||
|
||||
|
||||
|
||||
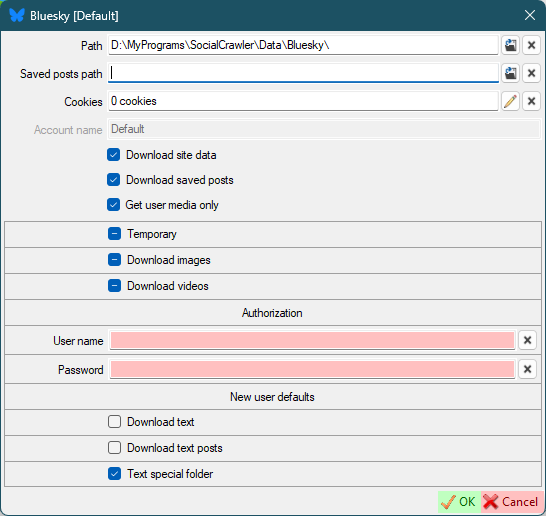
## Bluesky
|
||||
- `User name`- your account username (handle)
|
||||
- `Password` - your account password
|
||||
|
||||
|
||||
|
||||
### Bluesky requirements
|
||||
- `User name`
|
||||
- `Password`
|
||||
|
||||
## OnlyFans
|
||||
|
||||
**[Partial support](#paid-sites-partial-support)**
|
||||
@@ -500,6 +520,18 @@ To support the downloading of this site you should add the Mastodon domain to th
|
||||
- [`x-csrftoken`](#how-to-find-headers)
|
||||
- [`x-ig-app-id`](#how-to-find-headers)
|
||||
|
||||
### Instagram tips
|
||||
|
||||
**Join our [Discord channel](https://discord.gg/uFNUXvFFmg) to stay up to date with the latest changes and helpful tips!**
|
||||
|
||||
- If your browser has been updated, **immediately update** ALL fields in the SC for Instagram + cookies!
|
||||
- If your credentials have expired, don't forget to re-check all download options you need (`Download data` block) after updating your credentials.
|
||||
- Allow Instagram to use third-party cookies.
|
||||
- If you see a notification on Instagram such as `suspicious action`, dismiss it and update your Instagram credentials in SC.
|
||||
- **Download new profiles one by one. Wait for some time after downloading the new profile.**
|
||||
- If the user has **too many stories**, SC often throws an error. I recommend disabling their downloading. If you extremely need to download them, download them once and disable downloading after. Or create a scheduler plan to download them less often.
|
||||
- I recommend you to update your credentials **before** downloading **a large profile**. And after that, wait at least an hour to continue downloading any Instagram accounts. And I also recommend you to update your credentials once again after download a large account.
|
||||
|
||||
### Instagram limits
|
||||
|
||||
Instagram API is requests limited. For one request, the program receive only 50 posts. Before catching error 429, the program can process 200 requests. I reduced this to 195 requests and set a timer to wait for the next request after. This was added to bypass error 429 and prevent account ban.
|
||||
@@ -600,6 +632,7 @@ result_cancel-->[*]
|
||||
- New user defaults
|
||||
- `Download photos`
|
||||
- `Download videos`
|
||||
- `Download reels`
|
||||
- `Download stories`
|
||||
- Timers
|
||||
- `Request timer (any)` - the timer (in milliseconds) that SCrawler should wait before executing the next request. The default value is 1'000. **It is highly recommended not to change the default value.**
|
||||
@@ -725,6 +758,14 @@ for /f "usebackq tokens=*" %a in (`dir /S /B "c:/wamp64/www/YouTube-operational-
|
||||
15. Verify that your API instance is reachable by trying to access: http://localhost/YouTube-operational-API/
|
||||
16. Add this URL to SCrawler YouTube settings `YouTube API host`
|
||||
|
||||
### YouTube operational API update
|
||||
To update, **stop** WampServer, **execute** the following commands **in administrator mode**, then **start** WampServer again.
|
||||
|
||||
```bash
|
||||
cd C:\wamp64\www\YouTube-operational-API\
|
||||
git pull https://github.com/Benjamin-Loison/YouTube-operational-API
|
||||
```
|
||||
|
||||
## Pinterest
|
||||
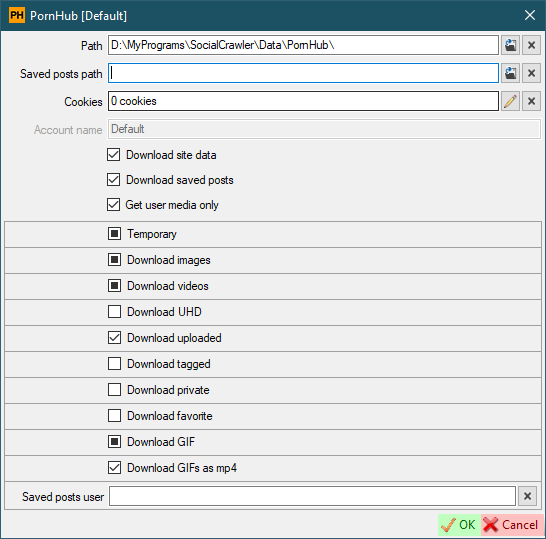
- `Concurrent downloads` - the number of concurrent downloads.
|
||||
- `Saved posts user` - personal profile username.
|
||||
@@ -782,7 +823,6 @@ if exist %p% (
|
||||
- `Download favorite` - download favorite videos.
|
||||
- `Download GIF` - default for new users.
|
||||
- `Download GIFs as mp4` - download gifs in 'mp4' format instead of native 'webm'.
|
||||
- `Photo ModelHub only` - download photo only from ModelHub. Prornstar photos hosted on PornHub itself will not be downloaded. **Attention! Downloading photos hosted on PornHub is a very heavy job.**
|
||||
- `Saved posts user` - personal profile username (to download saved posts)
|
||||
|
||||
|
||||
@@ -954,7 +994,7 @@ This command can be a batch command or any script file (bat, ps1 or whatever you
|
||||
1. Paste the copied cookies text into the window that opens (or press `Ctrl+O` to load cookies from a saved file (if you saved cookies to a file)) and click `OK`.
|
||||
1. Click OK to close the cookies editor and save the cookies.
|
||||
|
||||
Another similar extension: [Official site](https://cookie-editor.com/), [Chrome Web Store](https://chromewebstore.google.com/detail/cookie-editor/hlkenndednhfkekhgcdicdfddnkalmdm)
|
||||
**Another similar extension: [Official site](https://cookie-editor.com/), [Chrome Web Store](https://chromewebstore.google.com/detail/cookie-editor/hlkenndednhfkekhgcdicdfddnkalmdm)**
|
||||
|
||||
## Second method
|
||||
1. Open Google Chrome, Microsoft Edge or FireFox.
|
||||
|
||||
@@ -62,7 +62,7 @@ I want to download this artist: https://music.youtube.com/channel/UC25tCnonOu_M3
|
||||
2. Go to the following URL: https://music.youtube.com/channel/UC25tCnonOu_M3ojPEi57nWA
|
||||
3. To the right of the albums, click on the `More` button.
|
||||
4. Scroll down to the bottom of the page.
|
||||
5. In the dev tools, look for the last page that starts with `https://music.youtube.com/youtubei/v1/browse?key=..........`.
|
||||
5. In the dev tools, look for the last page that starts with `https://music.youtube.com/youtubei/v1/browse?key=..........` or `https://music.youtube.com/youtubei/v1/browse?prettyPrint=false`.
|
||||
6. Open the `Response` tab.
|
||||
7. Copy all text.
|
||||
8. Open the YouTube app.
|
||||
|
||||
Reference in New Issue
Block a user